Temporal Network Kernel Density Estimate
Jeremy Gelb
2025-10-04
Source:vignettes/TNKDE.Rmd
TNKDE.RmdIntroduction
Events recorded on a network often have a temporal dimension. In that context, one could estimate the density of events in both time and network spaces.
The spatio-temporal kernel is calculated as the product of the network kernel density and the time kernel density. For a sample point at location l and time t, the Temporal Network Kernel Density Estimate (TNKDE) is calculated as follows:
\[tnkde(l,t) = \frac{1}{bw_{net} * bw_{time}} * \sum^n_{i=1}(k_{net}(d(l,i_l),bw_{net})*k_{time}(d(t,i_t),bw_{time}))\]
with:
- \(k_{net}\) the network kernel density function
- \(k_{time}\) the time kernel density function
- \(bw_{net}\) the bandwidth used for the network kernel
- \(bw_{time}\) the bandwidth used for the time kernel
- n the number of events
- i an event at location \(i_l\) and time \(i_t\)
- \(d(a,b)\) the distance (in time or space) between a and b
As specified in the previous formula, two bandwidths are necessary, one for space and one for time.
We give in this vignette a short example with the bike accidents data in 2016 in the central districts of Montreal.
Temporal dimension
We start here by exploring the density of events in time.
# first load data and packages
library(spNetwork)
library(tmap)
library(sf)
data(bike_accidents)
# converting the Date field to a numeric field (counting days)
bike_accidents$Time <- as.POSIXct(bike_accidents$Date, format = "%Y/%m/%d")
start <- as.POSIXct("2016/01/01", format = "%Y/%m/%d")
bike_accidents$Time <- difftime(bike_accidents$Time, start, units = "days")
bike_accidents$Time <- as.numeric(bike_accidents$Time)
months <- as.character(1:12)
months <- ifelse(nchar(months)==1, paste0("0", months), months)
months_starts_labs <- paste("2016/",months,"/01", sep = "")
months_starts_num <- as.POSIXct(months_starts_labs, format = "%Y/%m/%d")
months_starts_num <- difftime(months_starts_num, start, units = "days")
months_starts_num <- as.numeric(months_starts_num)
months_starts_labs <- gsub("2016/", "", months_starts_labs, fixed = TRUE)
ggplot(bike_accidents) +
geom_histogram(aes(x = Time), bins = 30, color = "white") +
scale_x_continuous(breaks = months_starts_num, labels = months_starts_labs)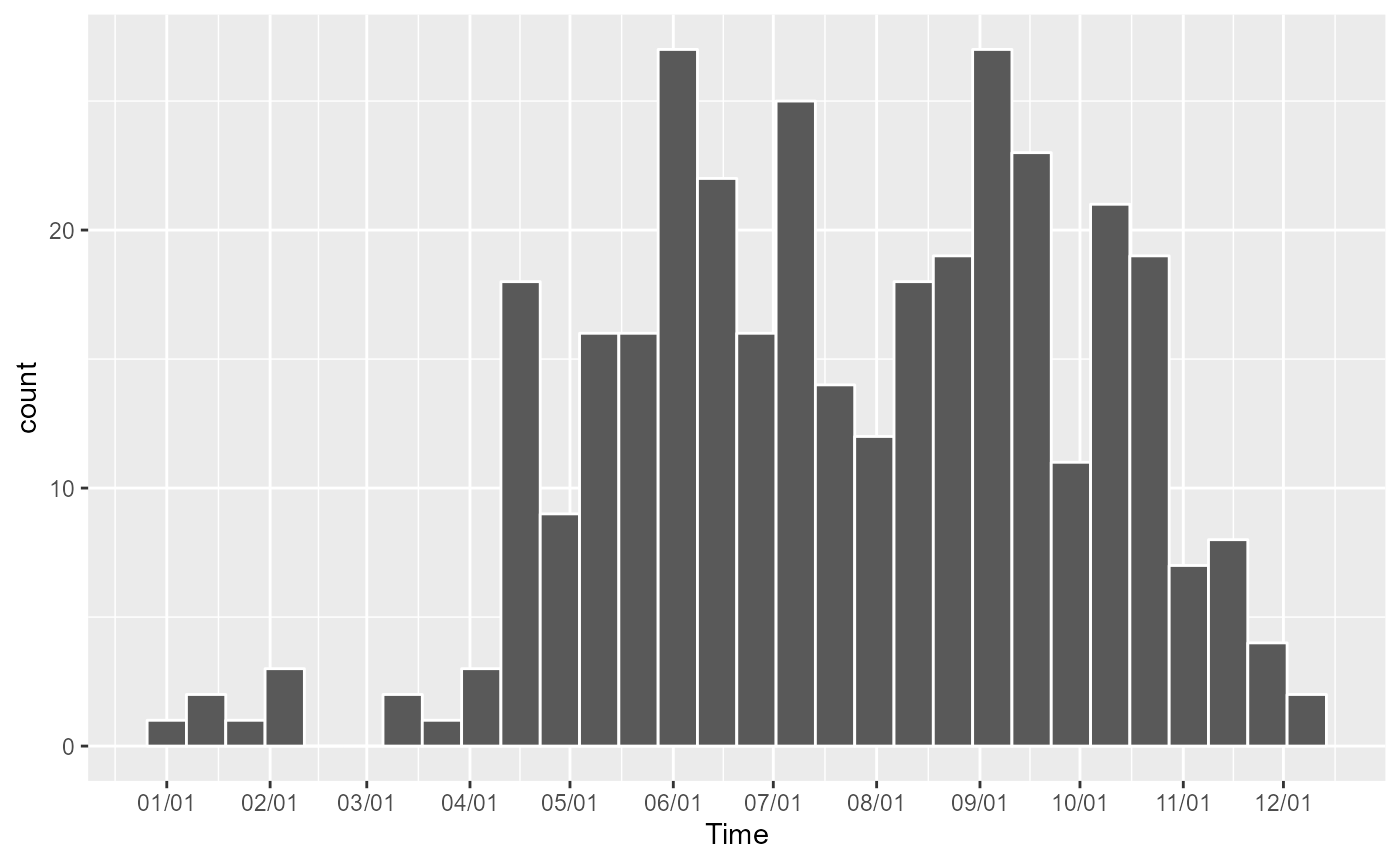
It is not surprising to observe that most of the accidents occur during spring, summer, and fall. We will remove the lonely observations during the first three months of the year because they might influence the bandwidths’ size latter.
bike_accidents <- subset(bike_accidents, bike_accidents$Time >= 90)We can now calculate the kernel density values in time for several bandwidths.
w <- rep(1,nrow(bike_accidents))
samples <- seq(0, max(bike_accidents$Time), 0.5)
time_kernel_values <- data.frame(
bw_10 = tkde(bike_accidents$Time, w = w, samples = samples, bw = 10, kernel_name = "quartic"),
bw_20 = tkde(bike_accidents$Time, w = w, samples = samples, bw = 20, kernel_name = "quartic"),
bw_30 = tkde(bike_accidents$Time, w = w, samples = samples, bw = 30, kernel_name = "quartic"),
bw_40 = tkde(bike_accidents$Time, w = w, samples = samples, bw = 40, kernel_name = "quartic"),
bw_50 = tkde(bike_accidents$Time, w = w, samples = samples, bw = 50, kernel_name = "quartic"),
bw_60 = tkde(bike_accidents$Time, w = w, samples = samples, bw = 60, kernel_name = "quartic"),
time = samples
)
df_time <- reshape2::melt(time_kernel_values,id.vars = "time")
df_time$variable <- as.factor(df_time$variable)
ggplot(data = df_time) +
geom_line(aes(x = time, y = value)) +
scale_x_continuous(breaks = months_starts_num, labels = months_starts_labs) +
facet_wrap(vars(variable), ncol=2, scales = "free") +
theme(axis.text = element_text(size = 5))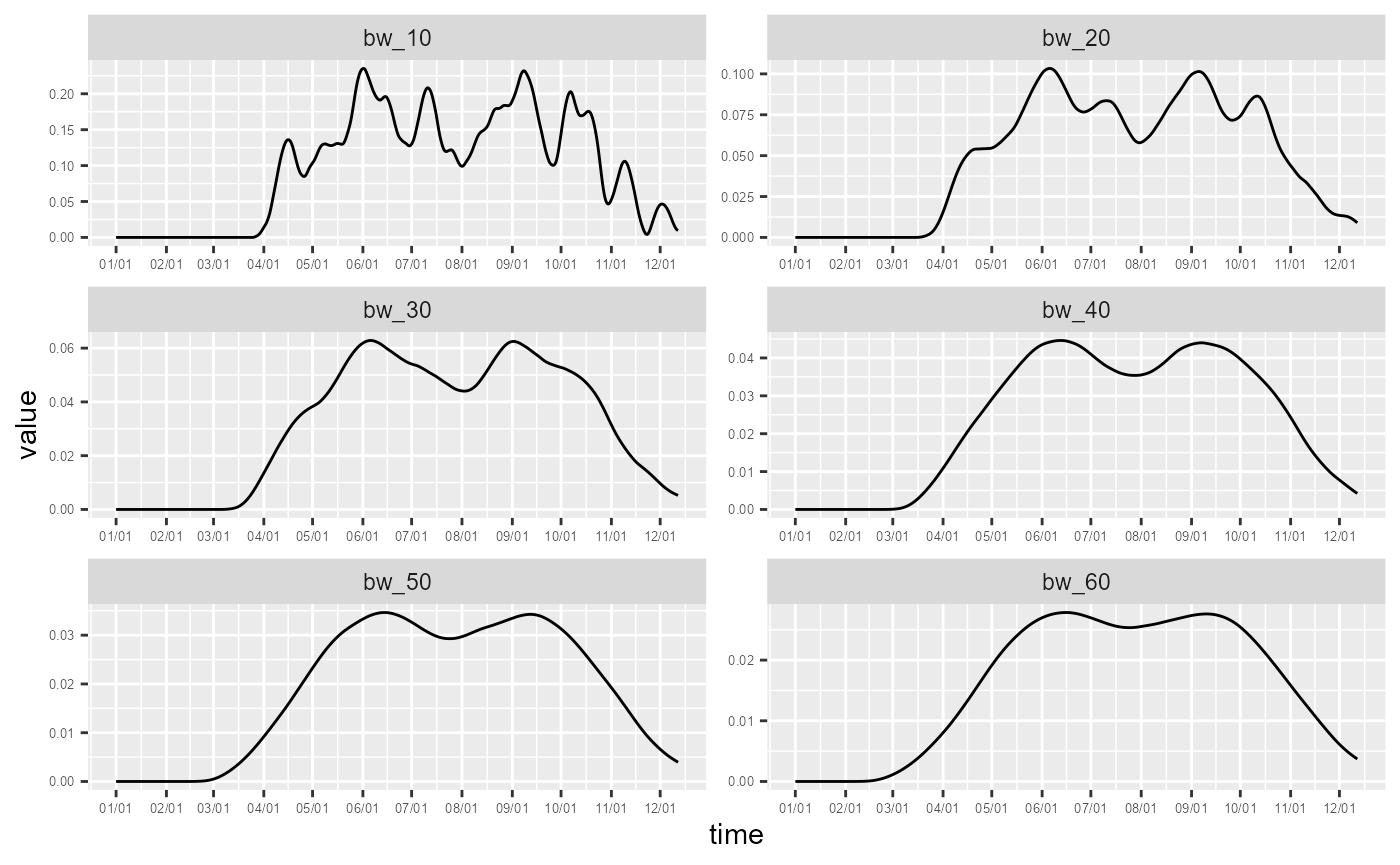
It seems that a bandwidth between 30 and 40 days capture the bimodal shape of the temporal dimension of bike accidents. The lower densities during July and August are likely caused by the lower traffic due to holidays.
It is also possible to use the classical functions from R to find a bandwidth with a data-driven approach.
bw1 <- bw.bcv(bike_accidents$Time, nb = 1000, lower = 1, upper = 80)
bw2 <- bw.ucv(bike_accidents$Time, nb = 1000, lower = 1, upper = 80)
bw3 <- bw.SJ(bike_accidents$Time, nb = 1000, lower = 1, upper = 80)
time_kernel_values <- data.frame(
bw_bcv = tkde(bike_accidents$Time, w = w, samples = samples, bw = bw1, kernel_name = "quartic"),
bw_ucv = tkde(bike_accidents$Time, w = w, samples = samples, bw = bw2, kernel_name = "quartic"),
bw_SJ = tkde(bike_accidents$Time, w = w, samples = samples, bw = bw3, kernel_name = "quartic"),
time = samples
)
df_time <- reshape2::melt(time_kernel_values,id.vars = "time")
df_time$variable <- as.factor(df_time$variable)
ggplot(data = df_time) +
geom_line(aes(x = time, y = value)) +
scale_x_continuous(breaks = months_starts_num, labels = months_starts_labs) +
facet_wrap(vars(variable), ncol=2, scales = "free") +
theme(axis.text = element_text(size = 5))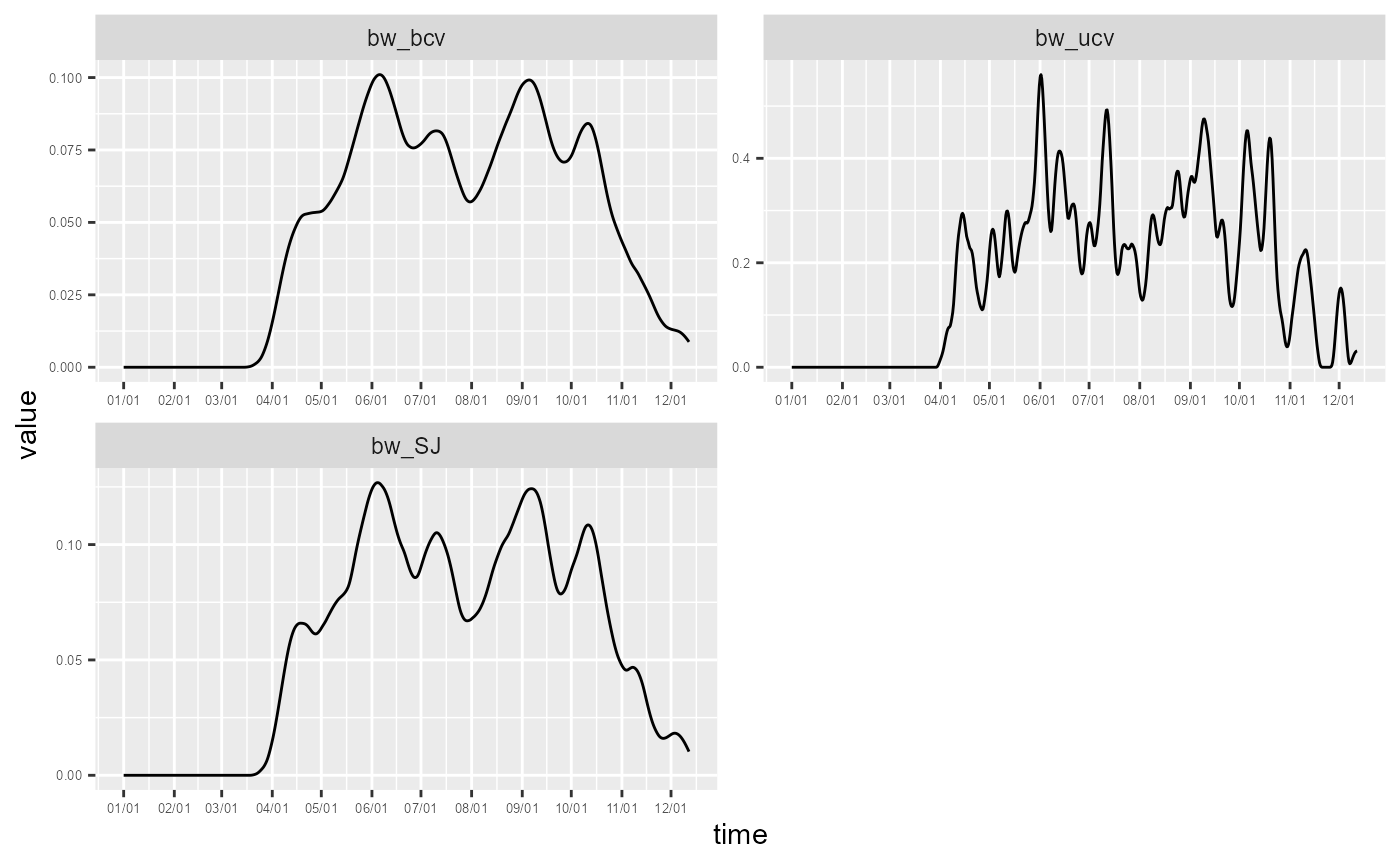
In that case, the automatic bandwidth selection methods yield much noisier results with small bandwidths. Bike accidents are rare events and too small time bandwidths would create results with meaningless hot spots.
Spatial dimension
Before considering the spatio-temporal case, we can also investigate the spatial dimension.
# loading the road network
data(mtl_network)
tm_shape(mtl_network) +
tm_lines(col = "black") +
tm_shape(bike_accidents) +
tm_dots(col = "red", size = 0.1)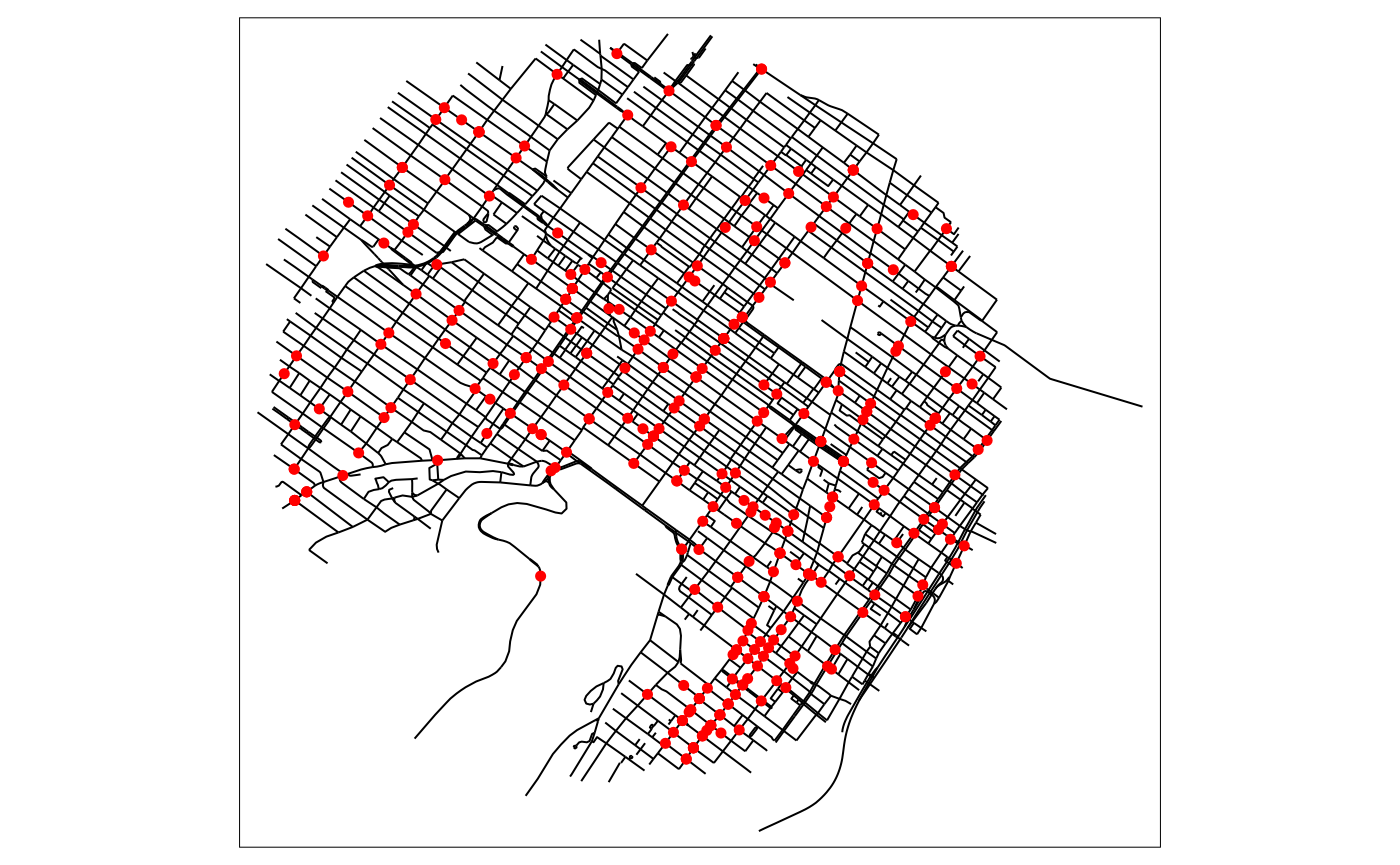
As suggested in the vignette NKDE, we will use an adaptive bandwidth of 450 metres for the discontinuous kernel.
# creating sample points
lixels <- lixelize_lines(mtl_network, 50)
sample_points <- lines_center(lixels)
# calculating the densities
nkde_densities <- nkde(lines = mtl_network,
events = bike_accidents,
w = rep(1,nrow(bike_accidents)),
samples = sample_points,
kernel_name = "quartic",
bw = 450,
adaptive = TRUE, trim_bw = 900,
method = "discontinuous",
div = "bw",
max_depth = 10,
digits = 2, tol = 0.1, agg = 5,
grid_shape = c(1,1),
verbose = FALSE)
sample_points$density <- nkde_densities$k * 1000
tm_shape(sample_points) +
tm_dots(col = "density", style = "kmeans", n = 8, palette = "viridis", size = 0.05) +
tm_layout(legend.outside = TRUE)
Several hot spots could already be identified, but we have no information about their location in time. The previous map represents the average density during the full period.
Spatio-temporal
We can now estimate the kernel density in both space and time. Note that increasing the dimension leads to larger bandwidths.
cv_scores <- bw_tnkde_cv_likelihood_calc(
bw_net_range = c(200,1100),
bw_net_step = 100,
bw_time_range = c(10,70),
bw_time_step = 10,
lines = mtl_network,
events = bike_accidents,
time_field = "Time",
w = rep(1, nrow(bike_accidents)),
kernel_name = "quartic",
method = "discontinuous",
diggle_correction = FALSE,
study_area = NULL,
max_depth = 10,
digits = 2,
tol = 0.1,
agg = 10,
sparse=TRUE,
grid_shape=c(1,1),
sub_sample=1,
verbose = FALSE,
check = TRUE)
knitr::kable(cv_scores)| 10 | 20 | 30 | 40 | 50 | 60 | 70 | |
|---|---|---|---|---|---|---|---|
| 200 | -587.79223 | -484.37649 | -447.25615 | -402.62454 | -359.90844 | -333.47735 | -290.83436 |
| 300 | -491.89552 | -364.06102 | -302.83071 | -240.07942 | -199.44797 | -159.08045 | -132.69855 |
| 400 | -398.35016 | -233.82688 | -183.01995 | -134.48349 | -102.07911 | -79.86527 | -69.71086 |
| 500 | -270.20411 | -134.31143 | -83.67591 | -59.44633 | -47.24880 | -31.15609 | -31.15963 |
| 600 | -190.88014 | -99.59826 | -63.25208 | -41.06763 | -32.98143 | -28.97901 | -27.04417 |
| 700 | -132.14033 | -71.17087 | -44.99185 | -32.91075 | -28.88226 | -24.94382 | -25.03437 |
| 800 | -105.43876 | -52.89761 | -34.78318 | -28.82551 | -28.86417 | -24.95098 | -25.05960 |
| 900 | -73.14578 | -42.66895 | -30.68143 | -26.79686 | -26.88695 | -24.99905 | -25.11791 |
| 1000 | -66.75178 | -38.62340 | -28.69409 | -26.82192 | -26.93382 | -25.06026 | -25.18601 |
| 1100 | -64.62978 | -38.57871 | -28.71002 | -26.86232 | -26.99215 | -25.12769 | -25.25853 |
According to the “leave one out cross validation” method, the optimal set of bandwidths is 700 metres and 60 days. As expected, larger bandwidths are required because the density of the events are spread both in space and time.
# choosing sample in times (every 10 days)
sample_time <- seq(0, max(bike_accidents$Time), 10)
# calculating densities
tnkde_densities <- tnkde(lines = mtl_network,
events = bike_accidents,
time_field = "Time",
w = rep(1, nrow(bike_accidents)),
samples_loc = sample_points,
samples_time = sample_time,
kernel_name = "quartic",
bw_net = 700, bw_time = 60,
adaptive = TRUE,
trim_bw_net = 900,
trim_bw_time = 80,
method = "discontinuous",
div = "bw", max_depth = 10,
digits = 2, tol = 0.01,
agg = 15, grid_shape = c(1,1),
verbose = FALSE)
# creating a color palette for all the densities
library(classInt)
library(viridis)
all_densities <- c(tnkde_densities$k)
color_breaks <- classIntervals(all_densities, n = 10, style = "kmeans")
# generating a map at each sample time
all_maps <- lapply(1:ncol(tnkde_densities$k), function(i){
time <- sample_time[[i]]
date <- as.Date(start) + time
sample_points$density <- tnkde_densities$k[,i]
map1 <- tm_shape(sample_points) +
tm_dots(col = "density", size = 0.01,
breaks = color_breaks$brks, palette = viridis(10)) +
tm_layout(legend.show=FALSE, main.title = as.character(date), main.title.size = 0.5)
return(map1)
})
# creating a gif with all the maps
tmap_animation(all_maps, filename = "images/animated_map.gif",
width = 1000, height = 1000, dpi = 300, delay = 50)
knitr::include_graphics("images/animated_map.gif")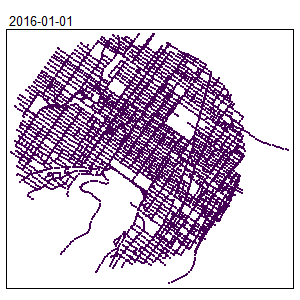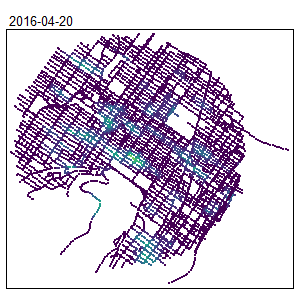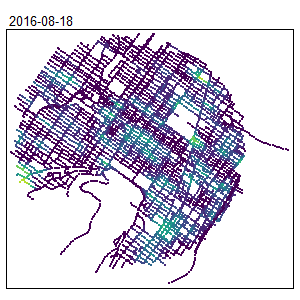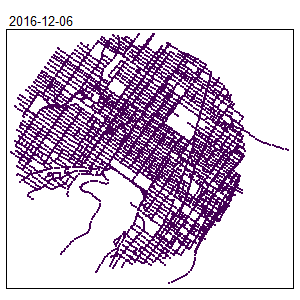
The locations of the hot spots are changing during the year. This information was hidden when only a spatial NKDE was used.
Adaptive bandwidth
One can decide to use adaptive bandwidth for the TNKDE. They are calculated using the Abramson’s smoothing regimen. Two approaches are available: separated and simultaneous. In the first case, the network and temporal density at each event location are calculated separately and used to calculate the local bandwidth. Isolated events on the network will obtain larger network bandwidth and isolated events in time will obtain larger time bandwidth. The second method calculates the temporal-network density at each event location and uses it to adjust both bandwidths simultaneously. This method will always lead to stronger variation in the local bandwidths.
We can also select the global bandwidth by cross validation with the
function bw_tnkde_cv_likelihood_calc.
cv_scores_adpt_dis <- bw_tnkde_cv_likelihood_calc(
bws_net = seq(200,1100,100),
bws_time = seq(10,70,10),
lines = mtl_network,
events = bike_accidents,
time_field = "Time",
adaptive = TRUE,
trim_net_bws = seq(200,1100,100)*2,
trim_time_bws = seq(10,70,10)*2,
w = rep(1, nrow(bike_accidents)),
kernel_name = "quartic",
method = "discontinuous",
diggle_correction = FALSE,
study_area = NULL,
max_depth = 10,
digits = 2,
tol = 0.1,
agg = 15,
sparse=TRUE,
grid_shape=c(1,1),
sub_sample=1,
verbose = FALSE,
check = TRUE)
cv_scores_adpt_cont <- bw_tnkde_cv_likelihood_calc.mc(
bws_net = seq(200,1100,100),
bws_time = seq(10,70,10),
lines = mtl_network,
events = bike_accidents,
time_field = "Time",
adaptive = TRUE,
trim_net_bws = seq(200,1100,100)*2,
trim_time_bws = seq(10,70,10)*2,
w = rep(1, nrow(bike_accidents)),
kernel_name = "quartic",
method = "continuous",
diggle_correction = FALSE,
study_area = NULL,
max_depth = 10,
digits = 2,
tol = 0.1,
agg = 15,
sparse=TRUE,
grid_shape=c(2,2),
sub_sample=1,
verbose = FALSE,
check = TRUE)
knitr::kable(cv_scores_adpt_cont)| 10 | 20 | 30 | 40 | 50 | 60 | 70 | |
|---|---|---|---|---|---|---|---|
| 200 | -338.97156 | -292.67876 | -256.54268 | -224.32854 | -196.12899 | -165.89033 | -151.78938 |
| 300 | -272.11249 | -189.42585 | -133.06588 | -104.92356 | -78.75489 | -56.66857 | -56.73603 |
| 400 | -211.52825 | -108.49115 | -74.37152 | -52.34423 | -38.33613 | -36.44768 | -32.55611 |
| 500 | -148.83060 | -68.21420 | -40.13708 | -34.23913 | -30.33736 | -26.47279 | -26.61781 |
| 600 | -98.28102 | -56.15372 | -38.22043 | -32.35431 | -26.49237 | -24.63671 | -24.78364 |
| 700 | -69.96942 | -48.15288 | -36.35146 | -28.46049 | -26.64667 | -24.78787 | -24.92030 |
| 800 | -67.94634 | -38.15245 | -30.41517 | -28.55644 | -24.73865 | -24.89479 | -25.03612 |
| 900 | -57.87576 | -34.18945 | -30.45321 | -26.63739 | -24.84289 | -25.00494 | -25.15676 |
| 1000 | -55.91859 | -34.27348 | -30.54284 | -26.74037 | -24.94655 | -25.11735 | -25.27390 |
| 1100 | -53.99004 | -32.35652 | -30.63396 | -30.90253 | -25.05495 | -25.22693 | -25.38587 |
For a discontinuous NKDE The best score is reached with a network and temporal bandwidths of 800m and 60 days.
tnkde_densities <- tnkde(lines = mtl_network,
events = bike_accidents,
time_field = "Time",
w = rep(1, nrow(bike_accidents)),
samples_loc = sample_points,
samples_time = sample_time,
kernel_name = "quartic",
bw_net = 800, bw_time = 60,
adaptive = TRUE,
adaptive_separate = FALSE,
trim_bw_net = 1000,
trim_bw_time = 80,
method = "discontinuous",
div = "bw", max_depth = 10,
digits = 2, tol = 0.01,
agg = 15, grid_shape = c(1,1),
verbose = FALSE)